Google Cloud Text-to-Speech
Text-to-Speech technology is now at a level where it can be used to replace human voice in applications. As now Google Cloud Text-to-Speech can convert text or Speech Synthesis Markup Language (SSML) input into audio data of natural human speech. Google Cloud Text-to-Speech enables developers to synthesize natural-sounding speech with over 200+ voices, available in multiple languages and variants. It applies DeepMind’s groundbreaking research in WaveNet and Google’s powerful neural networks to deliver the highest fidelity possible. Therefore, as an easy-to-use API, you can create lifelike interactions with your users, across many applications and devices.
Benefits of Google TTS
High fidelity speech Deploy Google’s groundbreaking technologies to generate speech with humanlike intonation. Built based on DeepMind’s speech synthesis expertise, the API delivers voices that are near human quality.
Widest voice selection Choose from a set of 220+ voices across 40+ languages and variants, including Mandarin, Hindi, Spanish, Arabic, Russian, and more. Where you can pick the voice that works best for your user and application.
One-of-a-kind voice Create a unique voice to represent your brand across all your customer touchpoints, instead of using a common voice shared with other organizations.
Basic example
Text-to-Speech is ideal for any application that plays audio of human speech to users. It allows you to convert arbitrary strings, words, and sentences into the sound of a person speaking the same things. Imagine that you have a voice assistant app that provides natural language feedback to your users as playable audio files. Your app might take an action and then provide human speech as feedback to the user.
Speech synthesis
The process of translating text input into audio data is called synthesis and the output of synthesis is called synthetic speech. Text-to-Speech takes two types of input: raw text or SSML-formatted data. To create a new audio file, you call the synthesize endpoint of the API. The speech synthesis process generates raw audio data as a base64-encoded string. You must decode the base64-encoded string into an audio file before an application can play it. Most platforms and operating systems have tools for decoding base64 text into playable media files.
Voices
Text-to-Speech creates raw audio data of natural, human speech. That is, it creates audio that sounds like a person talking. When you send a synthesis request to Text-to-Speech, you must specify a voice that ‘speaks’ the words. Text-to-Speech has a wide selection of custom voices available for you to use. The voices differ by language, gender, and accent (for some languages). For example, you can create audio that mimics the sound of a female English speaker with a British accent or you can also convert the same text into a different voice, say a male English speaker with an Australian accent.
WaveNet voices
Along with other, traditional synthetic voices, Text-to-Speech also provides premium, WaveNet-generated voices. Users find the Wavenet-generated voices to be more warm and human-like than other synthetic voices. The key difference to a WaveNet voice is the WaveNet model used to generate the voice. WaveNet models have been trained using raw audio samples of actual humans speaking. As a result, these models generate synthetic speech with more human-like emphasis and inflection on syllables, phonemes, and words.
Use cases
Voicebots in contact centers Deliver a better voice experience for customer service with voicebots on Dialogflow that dynamically generate speech, instead of playing static, pre-recorded audio. Engage with high-quality synthesized voices that give callers a sense of familiarity and personalization.
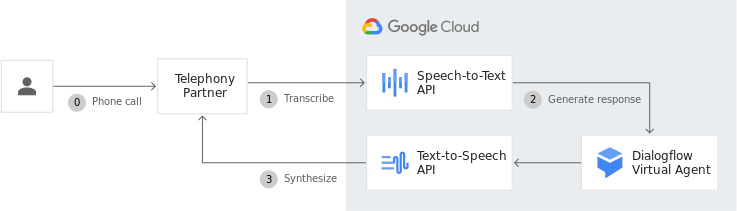
Voice generation in devices Enable natural communications with your users by empowering your devices to speak humanlike voices as a text reader. Build an end-to-end voice user interface together with Speech-to-Text and Natural Language to improve user experience with easy and engaging interactions.
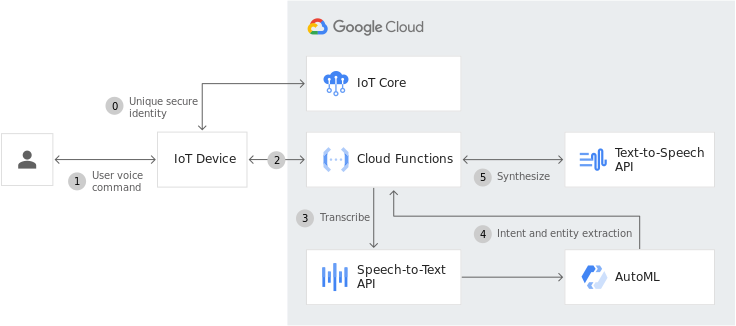
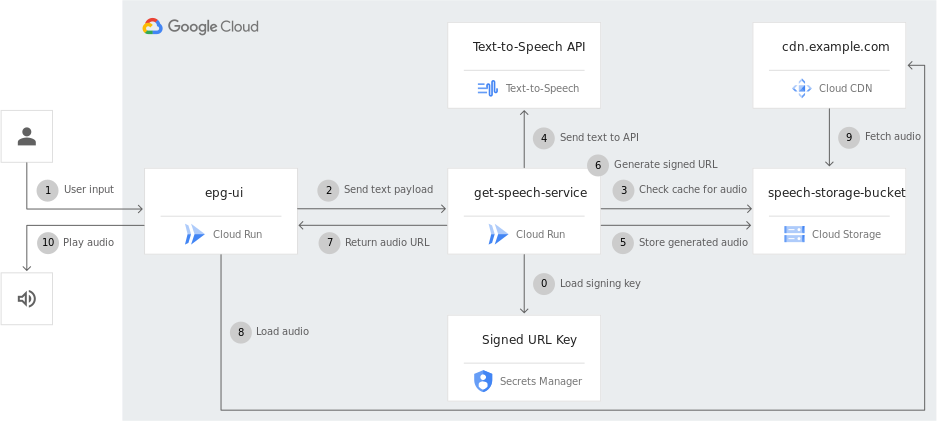
Accessible EPGs (Electronic Program Guides) Easily have the EPGs read text aloud to provide a better user experience to your customers and meet accessibility requirements for your services and applications. Also, easily implement text-to-speech functionality in EPGs to provide a better user experience to your customers and meet accessibility requirements for your services and applications.
Sum up for Google TTS: Convert text into natural-sounding speech using an API powered by Google’s AI technologies.
- Improve customer interactions with intelligent, lifelike responses
- Engage users with voice user interface in your devices and applications
- Personalize your communication based on user preference of voice and language
Try it for yourself
Go on and create an Google Cloud account to evaluate how Text-to-Speech performs in real-world scenarios.
線上諮詢
與我們合作,馬上展開全新的創作里程碑
- 📅 立即預約,30 秒完成!
- 🎯 與創辦人 1 對 1 交流,獲得專屬建議! 🎯 與創辦人 1 對 1 交流!