Llama 3.1 及其架構
在本節中,讓我們嘗試了解有關 Meta 的新 Llama 3 模型的所有細節。根據他們最近的公告,他們的旗艦開源模型擁有 4050 億個海量參數。據說該模型在幾乎所有基準測試中都擊敗了其他法學碩士(稍後會詳細介紹)。據說該模型具有卓越的功能,特別是考慮到常識、可操縱性、數學、工具使用和多語言翻譯。Llama 3.1對合成資料產生也有很好的支持。 Meta也提煉了這款旗艦型號,推出了Llama 3.1的另外兩款變體型號,包括Llama 3.1 8B和70B。
培訓方法
所有這些模型都是多語言的,具有 128K 標記的非常大的上下文視窗。它們專為在人工智慧代理中使用而構建,因為它們支援本機工具使用和函數呼叫功能。 Llama 3.1 聲稱在數學、邏輯和推理問題上更強。它支援多種高級用例,包括長格式文字摘要、多語言對話代理和編碼助理。他們還聯合訓練這些模型的圖像、音頻和視頻,使其成為多模態的。然而,多式聯運變體仍在測試中,截至今天(2024 年 7 月 24 日)尚未發布。鑑於 Llama 模型的整個系列,正如您在下面的快照中所看到的,這是第一個對工具進行本機支援的模型。這標誌著公司正在轉向專注於建立 Agentic AI 系統。
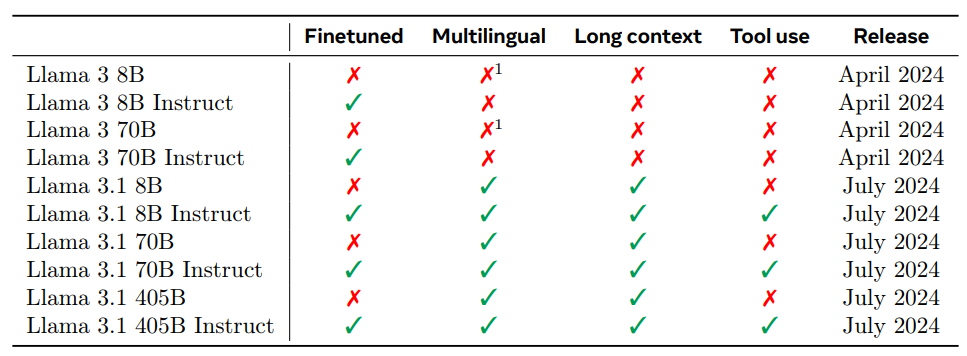
Llama 3 系列型號的比較;圖片來源:The Llama 3 Herd of Models,Meta
該法學碩士的發展由培訓過程中的兩個主要階段組成:
-
**預訓練:**這裡 Meta 將大型多語言文字語料庫標記為離散標記,然後根據經典語言建模任務的結果資料預訓練大型語言模型 (LLM) – 執行下一個標記預測。因此,該模型學習語言的結構,並從它所經歷的文本中獲得大量關於世界的知識。 Meta 大規模地做到了這一點,在他們的論文中,他們提到他們使用 8K 令牌的上下文視窗在 15.6T 令牌上預訓練了一個具有 405B 參數的模型。此標準預訓練階段之後是持續的預訓練階段,該階段將支援的上下文視窗增加到 128K 個令牌
-
**訓練後:**此步驟也俗稱微調。預先訓練的語言模型可以理解文本,但不能理解指令或意圖。在此步驟中,Meta 將模型與人類回饋進行多輪調整,每輪都涉及指令調整資料的監督微調 (SFT)和直接偏好最佳化(DPO;Rafailov 等人,2024)。他們還整合了工具使用等新功能,並專注於改進編碼和推理等任務。除此之外,安全緩解措施也已在訓練後階段納入模型中
架構細節
下圖展示了Llama 3.1模型的整體架構。 Llama 3 使用標準的、密集的Transformer 架構(Vaswani 等人,2017)。在模型架構方面,它與Llama 和 Llama 2沒有顯著偏離(Touvron et al., 2023) ; Meta 聲稱其效能提升主要是由資料品質和多樣性的改進以及訓練規模的擴大所推動的。
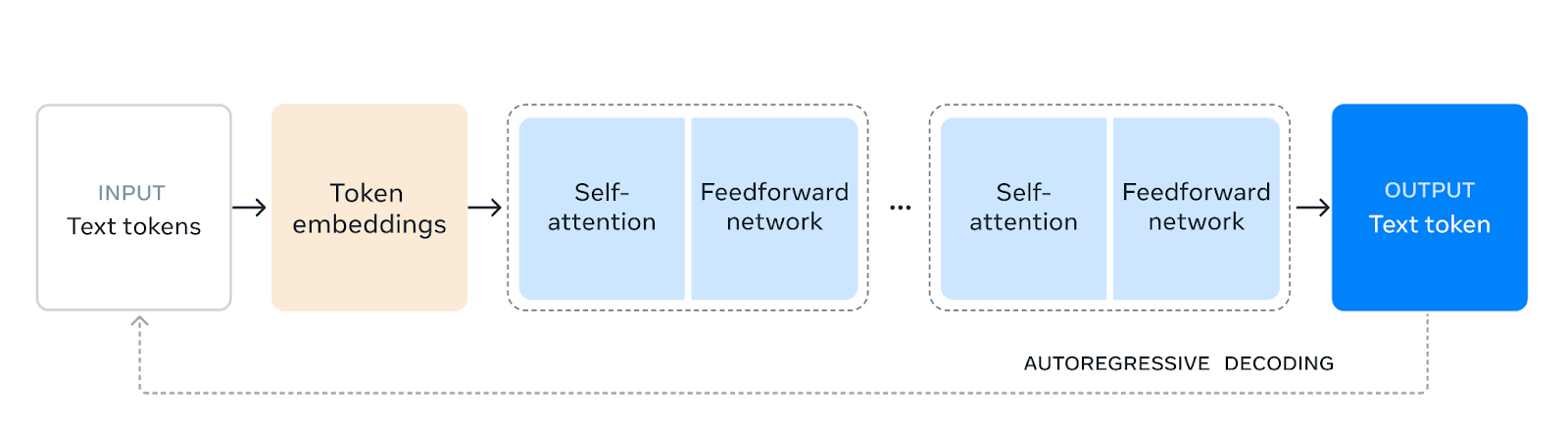
Llama 3.1 模型架構;圖片來源:The Llama 3 Herd of Models,Meta
Meta 也提到,他們使用了標準的僅解碼器變壓器模型架構(基本上是自回歸變壓器),並進行了細微的調整,而不是專家混合模型,以最大限度地提高訓練穩定性。然而,與 Llama 3 相比,他們確實對 Llama 3.1 進行了一些修改,其中包括他們的論文_The Llama 3 Herd of Models_中提到的以下內容:
-
使用具有 8 個鍵值頭的分組查詢注意力(GQA;Ainslie 等人(2023))可以提高推理速度並減少解碼期間鍵值快取的大小。
-
使用注意力遮罩來防止同一序列中不同文件之間的自註意力,這提高了效能,特別是對於長序列
-
使用具有 128K 個標記的詞彙表。他們的代幣詞彙將 tiktoken3 代幣生成器中的 100K 個代幣與 28K 個附加代幣相結合,以更好地支援非英語語言。
-
將 RoPE 基頻超參數增加至 500,000。這使得 Meta 能夠更好地支援更長的上下文;熊等人。 (2023) 顯示該值對於上下文長度高達 32,768 的情況有效
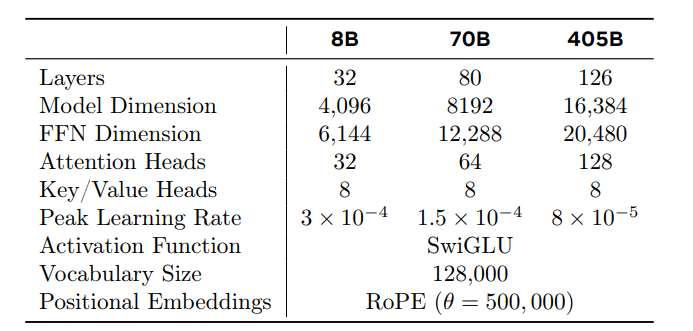
Llama 3.1的關鍵超參數;圖片來源:The Llama 3 Herd of Models,Meta
從上表可以明顯看出,Llama 3.1系列模型的關鍵超參數是Llama 3.1 405B使用126層的架構,16,384個token表示維度和128個注意力頭。此外,他們訓練這個模型的學習率比其他兩個較小的模型略低也就不足為奇了。
培訓後方法
對於訓練後過程(微調),他們專注於涉及拒絕採樣、監督微調和直接偏好優化的策略,如下圖所示。
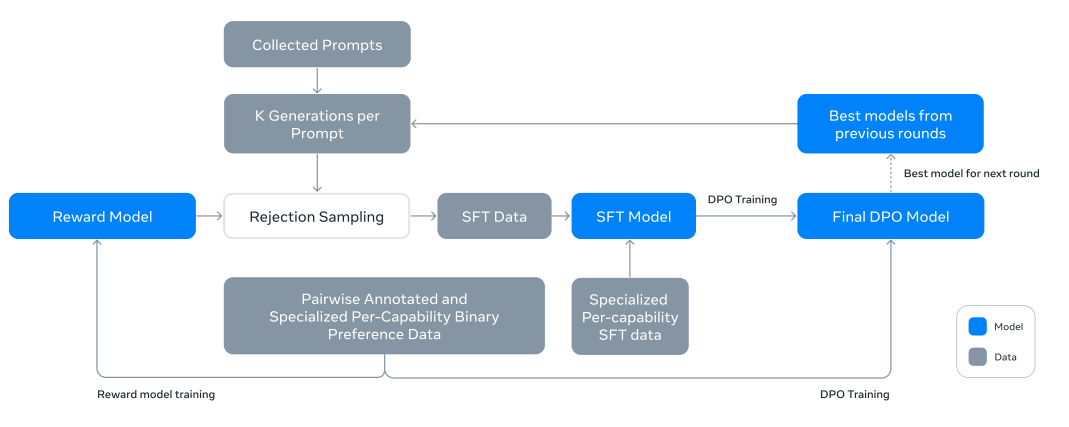
Llama 3.1 的訓練後(微調)過程;圖片來源:The Llama 3 Herd of Models,Meta
Meta 的 Llama 3.1 訓練後策略的支柱是獎勵模型和語言模型。使用人工註釋的偏好數據,他們首先在預先訓練的 Llama 3.1 檢查點之上訓練獎勵模型。該模型有助於對人工註釋資料進行拒絕採樣,其基於任務的微調資料集是人工生成資料和合成資料的組合,如下圖所示。
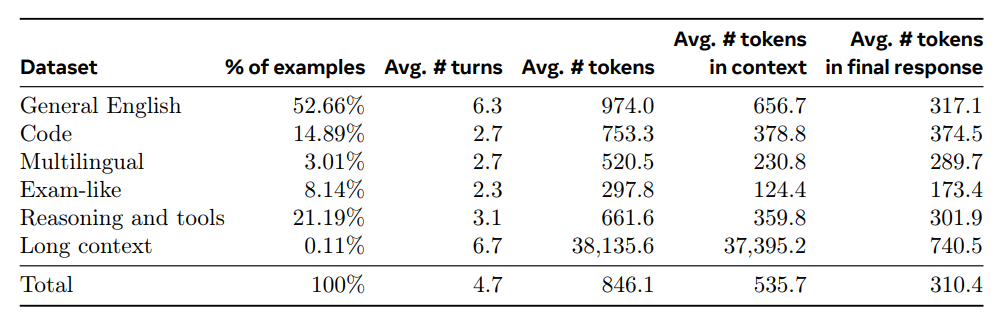
非常有趣的是,他們專注於創建各種基於任務的資料集,包括專注於編碼、推理、工具呼叫和長上下文任務。然後,他們在此資料集上使用監督微調 (SFT) 微調預訓練的檢查點,並透過直接偏好最佳化進一步調整檢查點。與先前版本的 Llama 相比,它們提高了訓練前和訓練後資料的數量和品質。在訓練後,他們透過在預訓練模型的基礎上進行幾輪對齊,產生了最終的指令調整聊天模型。每輪都涉及監督微調(SFT)、拒絕採樣(RS)和直接偏好優化(DPO)。提到了許多詳細的方面,不僅涉及訓練過程,還涉及他們使用的資料集和確切的工作流程。請參閱論文_The Llama 3 Herd of Models _Llama Team、AI @ Meta了解所有好東西!
Llama 3.1 效能比較
Meta 在各種標準基準資料集上對 Llama 3.1 的性能進行了重要測試,重點關注不同的任務,並將其與其他幾個大型語言模型 (LLM) 進行比較,包括 Claude 和GPT-4o。
基準評估
從下表中可以清楚地看出,它已迅速成為最新的最先進(SOTA)LLM,在幾乎每個基準資料集和任務中都擊敗了其他強大的模型。
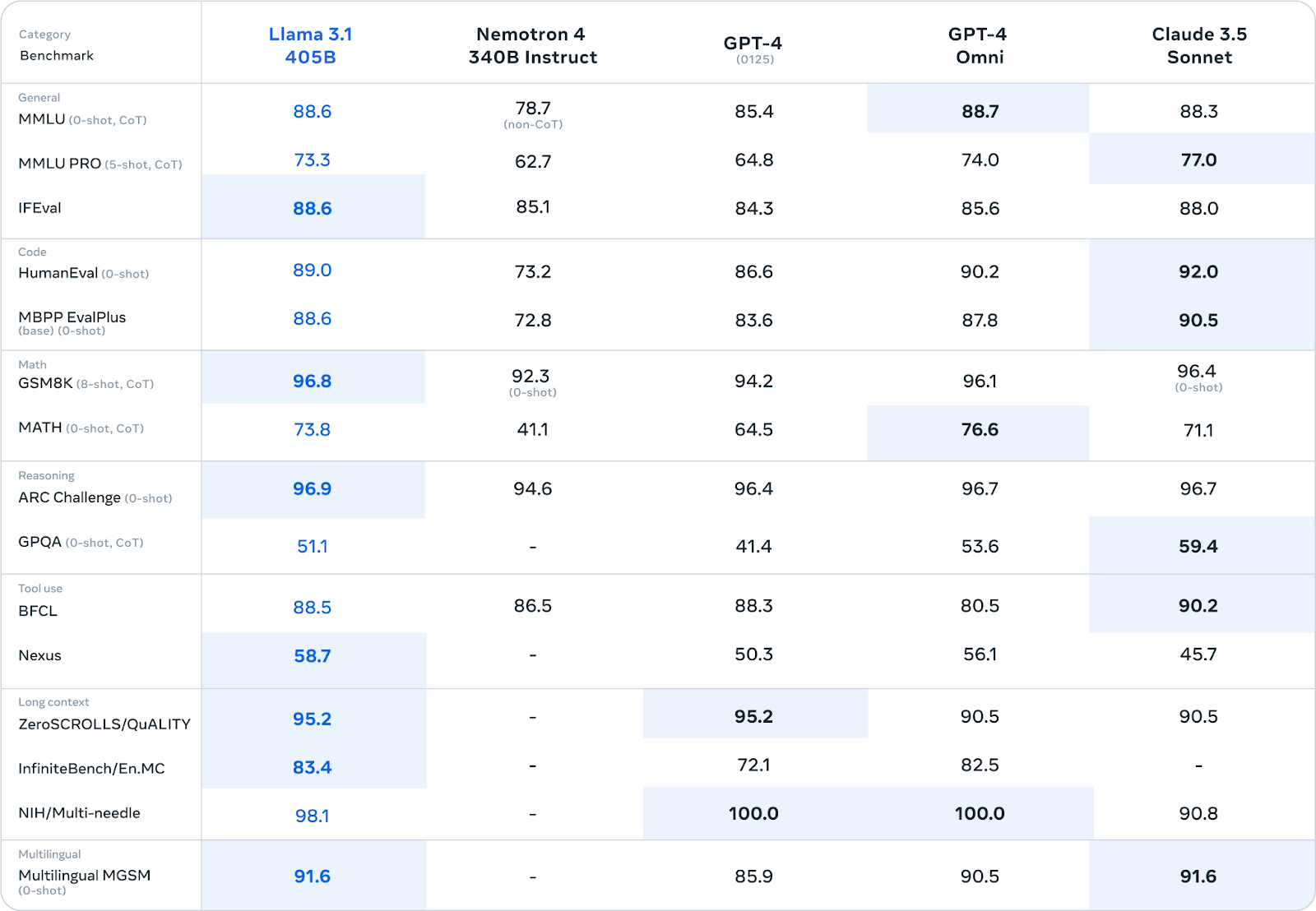
Llama 3.1 405B 的基準比較;圖片來源:Meta
Meta 也發布了兩個較小的 Llama 3.1 模型(8B 和 70B)的基準測試結果,將它們與類似模型進行了比較。令人驚訝的是,8B 模型在幾乎所有基準測試中都擊敗了 175B Open AI GPT-3.5 Turbo 模型。 Meta Llama 3.1 8B 模型的這些結果非常明顯地體現了對小語言模型 (SLM) 的進展和關注。
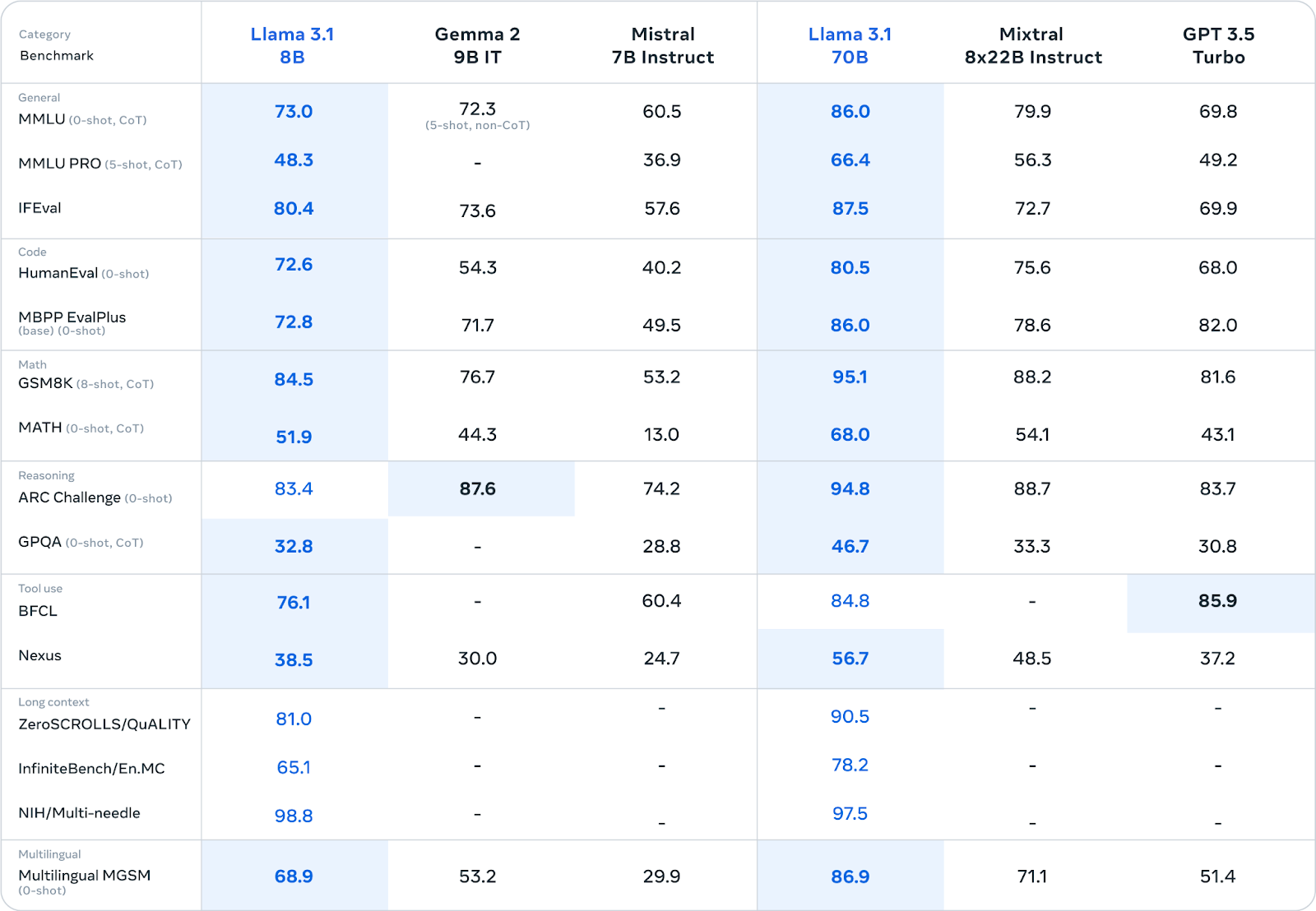
Llama 3.1 8B 與 70B 的基準比較;圖片來源:Meta
人類評價
除了基準測試之外,Meta 還使用人工評估流程將 Llama 3 405B 與 GPT-4(0125 API 版本)、GPT-4o(API 版本)和 Claude 3.5 Sonnet(API 版本)進行比較。為了對兩個模型進行成對的人類評估,他們詢問人類註釋者他們更喜歡兩個模型反應(由不同模型產生)中的哪一個。註釋者使用 7 分制進行評分,使他們能夠指示一個模型反應是否遠好於、好於、略好於或大致相同於另一個模型反應。
** 主要觀察結果包括:**
- Llama 3.1 405B 的效能與 GPT-4 的 0125 API 版本大致相當,但與 GPT-4o 和 Claude 3.5 Sonnet 相比,結果好壞參半(有些勝利,有些失敗)
- 在多輪推理和編碼任務上,Llama 3.1 405B 優於 GPT-4,但在多語言(印地語、西班牙語和葡萄牙語)提示上表現低於 GPT-4
- Llama 3.1 在英語提示上的表現與 GPT-4o 相當,在多語言提示上與 Claude 3.5 Sonnet 相當,在單輪和多輪英語提示上優於 Claude 3.5 Sonnet
- Llama 3.1 在編碼和推理等能力上落後於 Claude 3.5 Sonnet
效能比較
我們也透過Artificial Analysis進行了詳細的分析和比較,Artificial Analysis是一個獨立組織,為各種LLM和SLM提供基準測試和相關資訊。下圖將 Llama 3.1 系列中的各種模型與其他流行的 LLM 和 SLM 進行了比較,考慮了品質、速度和價格。總體而言,該模型似乎在這三個類別中都表現得很好,如下圖所示。
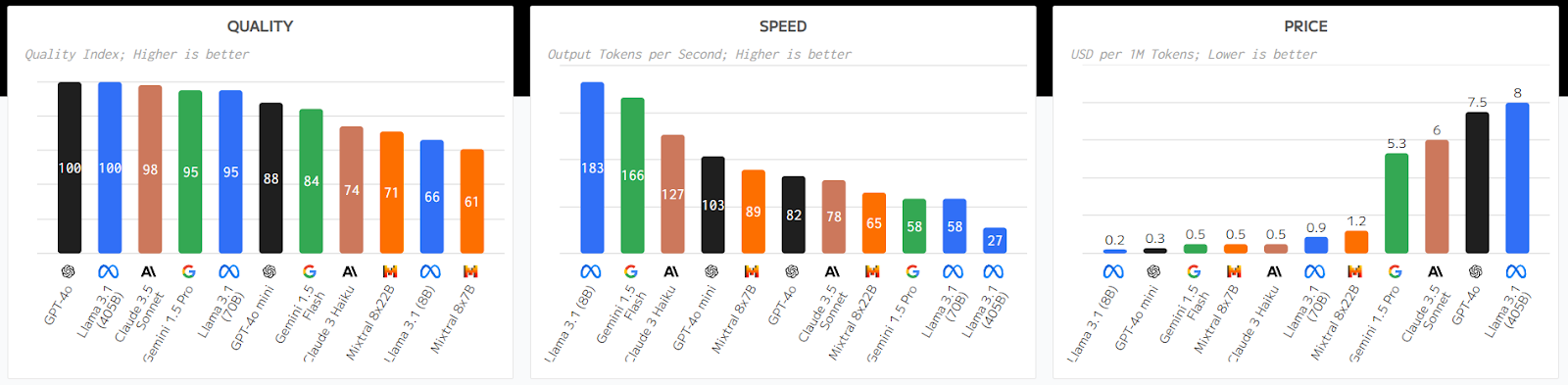
圖片來源:人工分析
除了模型在結果品質方面的表現外,我們在選擇 LLM 或 SLM 時通常會考慮幾個因素,其中包括反應速度和成本。考慮到這些因素,我們得到了各種比較,其中包括模型的** 輸出速度** ,它基本上側重於模型生成令牌時每秒接收到的輸出令牌(即從 API 接收到第一個區塊之後) 。這些數字是基於所有提供者的中位數速度,根據他們的觀察,Llama 3.1 的 8B 變體似乎給出反應的速度相當快。
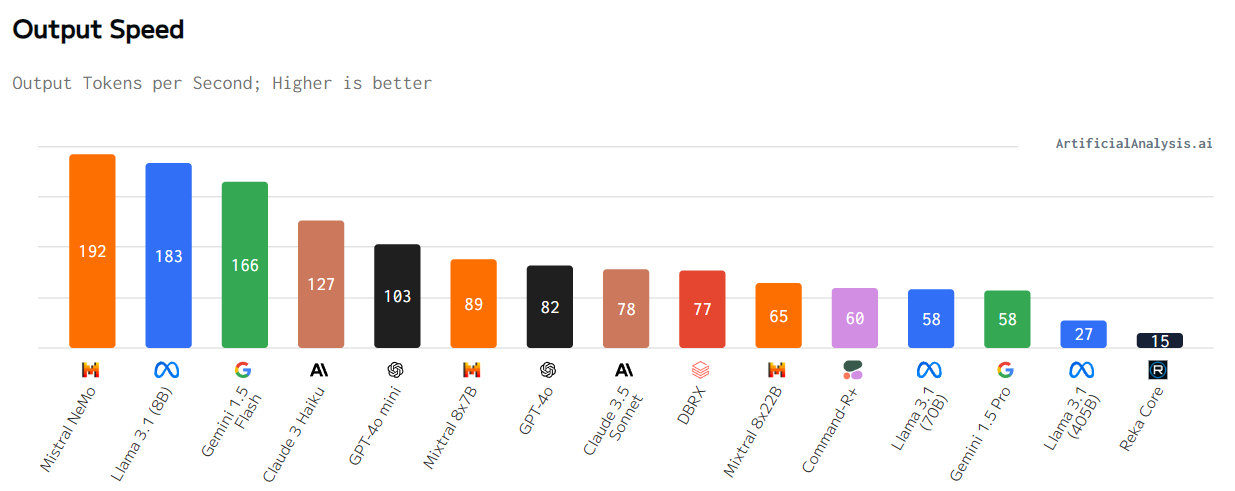
圖片來源:人工分析
Llama 3.1 供貨情況與定價比較
Meta 致力於讓所有人都能使用 Llama 3.1。 Llama 模型權重可供下載,您可以在 HuggingFace 上輕鬆存取它們。開發人員可以根據自己的需求和應用程式完全自訂模型,在新資料集上進行訓練,並進行額外的微調。基於 Meta在他們的網站上提到的內容。在第一天,開發人員就可以利用 Llama 3.1 的所有高級功能並立即開始建置。開發人員還可以探索先進的工作流程,例如易於使用的合成資料生成,遵循模型蒸餾的交鑰匙指示,並利用 AWS、NVIDIA、Databricks、Groq 等合作夥伴的解決方案實現無縫 RAG,如下圖所示。
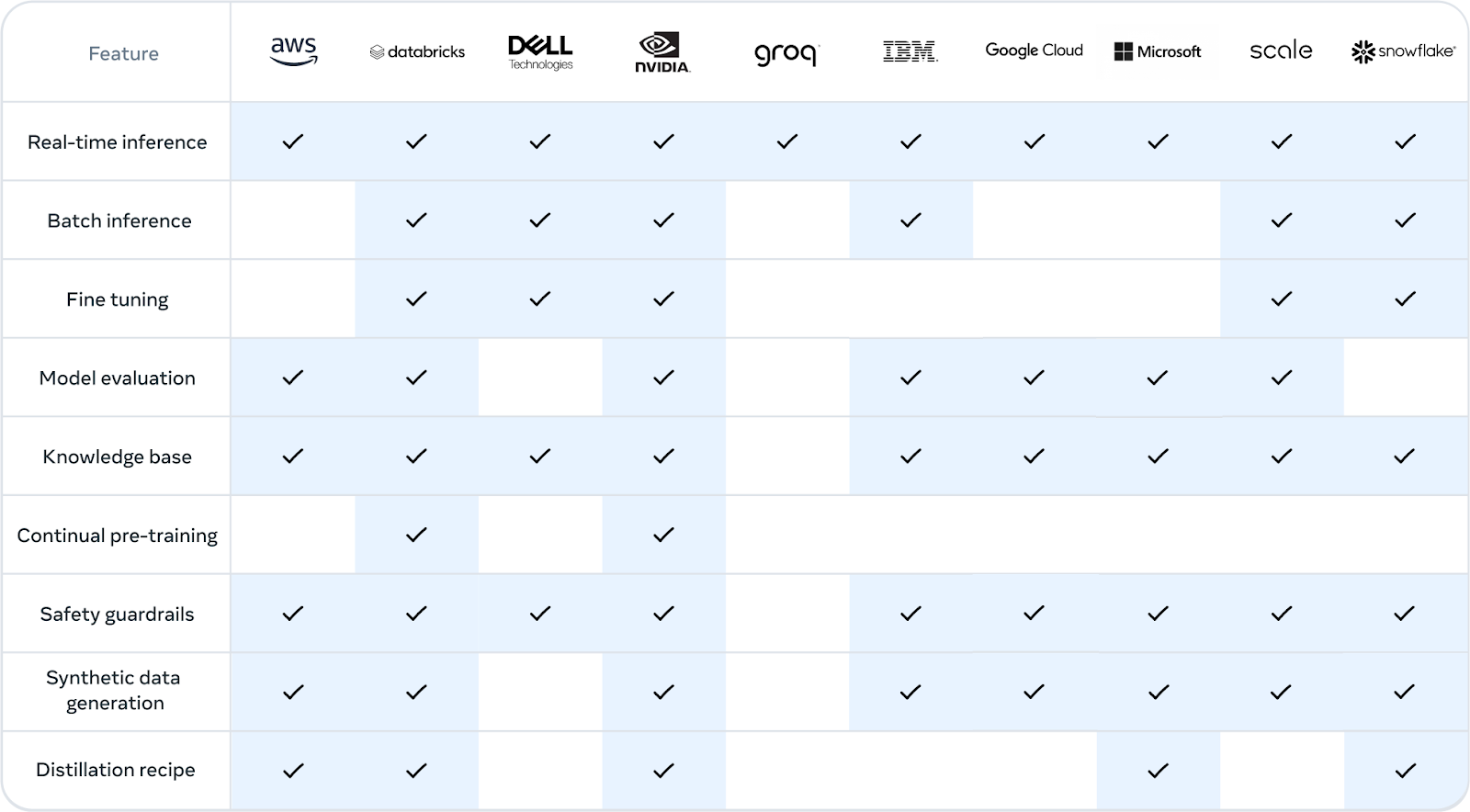
Llama 3.1 可用性;圖片來源:Meta AI
雖然很容易認為封閉模型具有成本效益,但 Meta 聲稱 Llama 3.1 既是開源的,並且基於詳細分析,在每代幣成本方面提供了一些業內最好和最便宜的模型通過人工分析完成。
以下是人工分析使用 Llama 3.1與其他流行模型****的成本的詳細比較。定價 以每 1M(百萬)代幣**的 **輸入提示和輸出響應來顯示。 Llama 3.1 相當便宜,而且非常接近 GPT-4o mini。較大的型號,如 Llama 3.1 405B,非常昂貴,並且與較大的 GPT-4o 型號類似。
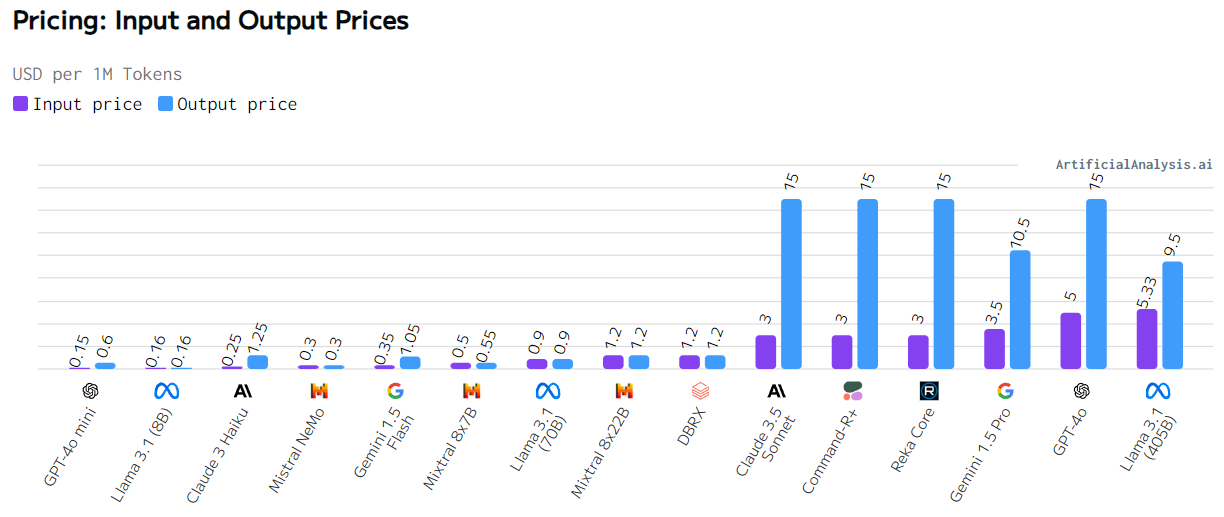
圖片來源:人工分析
總體而言,Llama 3.1 是 Meta 迄今為止最好的模型,它是開源的,基於其他模型的基準測試相當有競爭力,並且提高了複雜任務的性能,包括數學、編碼、推理和工具使用。
Overview
GPT-4o Mini was released 5 days before Llama 3.1 8B Instruct.
 GPT-4o Mini GPT-4o Mini |
 Llama 3.1 8B Instruct Llama 3.1 8B Instruct |
|
|---|---|---|
| ProviderThe entity that provides this model. | OpenAI |
Meta |
| Input Context WindowThe number of tokens supported by the input context window. | 128Ktokens | 128Ktokens |
| Maximum Output TokensThe number of tokens that can be generated by the model in a single request. | 16.4Ktokens | 2,048tokens |
| Release DateWhen the model was first released. | July 18th, 20249 days ago2024-07-18 | July 23rd, 20244 days ago2024-07-23 |
Pricing
| GPT-4o Mini |
Llama 3.1 8B Instruct |
|
|---|---|---|
| InputCost of input data provided to the model. | $0.15per million tokens | Pricing not available. |
| OutputCost of output tokens generated by the model. | $0.60per million tokens | Pricing not available. |
Benchmarks
Compare relevant benchmarks between GPT-4o Mini and Llama 3.1 8B Instruct.
| GPT-4o Mini |
Llama 3.1 8B Instruct |
|
|---|---|---|
| MMLUEvaluating LLM knowledge acquisition in zero-shot and few-shot settings. | 82.0(5-shot)Source | 66.7(5-shot)Source |
| MMMUA wide ranging multi-discipline and multimodal benchmark. | 59.4Source | Benchmark not available. |
| HellaSwagA challenging sentence completion benchmark. | Benchmark not available. | Benchmark not available. |
線上諮詢
與我們合作,馬上展開全新的創作里程碑
- 📅 立即預約,30 秒完成!
- 🎯 與創辦人 1 對 1 交流,獲得專屬建議! 🎯 與創辦人 1 對 1 交流!